“Trees are right at the heart of all the necessary debates: ecological, social, economic, political, moral, religious.” ― Colin Tudge
Introduction
As the previous quote by Colin Tudge, author of The Tree espouses, trees play an essential role in the daily lives of humans, animals, and plants. Recent research on the widespread benefits of trees in a myriad of areas from environmental to physical to socioeconomic well-being has led policymakers to become advocates for eliminating “concrete jungles” in their cities and expanding tree canopy coverage through the planting of urban forests and other green spaces (“Benefits of trees”, 2019; Endreny, 2018; Kabisch et al., 2017).
Early studies on these initiatives by environmental experts have found that urban forests reduce carbon emissions and mitigate global warming (Johnson et al., 2013; Malmsheimer et al., 2011; McPherson & Simpson, 1999; Russo et al., 2015; Zhao et al., 2010; Zheng et al., 2013). For example, a 2011 study conducted by the U.S. Forest Service iterated that that reducing greenhouse gases in the environment requires the creation of new forests (Malmsheimer et al., 2011), while an earlier study by McPherson & Simpson (1999) specifically focused on providing a guide for conservationists and business/industry executives to increase tree canopy coverage in communities and offset carbon dioxide emissions. Other studies such as those conducted by Johnson et al. (2013) and Russo et al. (2015) suggested urban forests as a way to reduce the effects of transportation on climate change and research by Zhao et al. (2010) and Zheng et al. (2013) provided overarching summaries of the benefits of urban forests.
Similarly, investigations performed by socioeconomic and public health researchers have simultaneously espoused that trees and urban green spaces have a positive correlation with health and well-being in human living environments (Daams & Veneri, 2016; Dadvand et al., 2014; Dadvand et al., 2018; De Vries et al., 2007; Donovan, 2017; Faber Taylor & Kuo, 2011; King et al., 2015; Reid et al., 2017; Taylor et al., 1998; Turner‐Skoff & Cavender, 2019; U.S. Department of Agriculture, Forest Service, 2018; Ulmer et al., 2016). Studies by Dadvand et al (2014), Dadvand et al. (2018), Faber Taylor & Kuo (2011), Kabisch et al. (2017), Reid et al. (2017), the U.S. Department of Agriculture, Forest Service (2018), and Ulmer et al. (2016) all found that urban green spaces have significant benefits on the physical and mental health and well-being of individuals, particularly those who suffer from chronic illnesses and developmental difficulties such as obesity, asthma, allergies, diabetes, and ADHD. Other research by De Vries et al. (2007) and King et al. (2015) explore urban forests as outlets for safe play in inner-city areas while Turner et al. (2019) highlighted that trees are important for creating sustainable living environments.
Following these scientific findings, cities have begun the task of creating databases to identify where trees are currently located in their communities and identify where new urban forests are needed (Poon, 2018). However, the financial and human capital required to create these databases, known as tree censuses, are substantial (Poon, 2018).
The city-wide TreesCount! census that was conducted in New York City, required 12,000 volunteer hours from 2,200 citizen mappers who were trained to utilize “high tech mapping tools with survey wheels, tape measures, and tree identification keys” according to a method developed by a non-profit organization, TreeKIT (“TreesCount!”, 2017). This volunteer work saved the city over $100,000 in survey costs, however even with such a large amount of volunteer hours, it took almost a year and a half to complete the census (“TreesCount!”, 2017). Although this was an intuitive way to save money and help “citizen mappers” and “citizen scientists” discover the importance of trees, many organizations do not have access to such a large pool of volunteers and/or are unable to wait years for results (Butt et al., 2013; Poon, 2018, “TreesCount!”, 2017). Therefore, cities and nonprofit groups are in dire need of a secondary assessment method that is quicker, less labor-intensive, and more affordable.
In recent years, remote spatial data analysis tools have emerged as a viable option (Li et al., 2019; Lin et al., 2015; Ren et al., 2015; Tigges & Lakes, 2017). Remote spatial data analysis is a broad field that relies on unmanned aerial vehicles (UAV) and remote sensing (RS) techniques to combine high-quality optical images and LiDAR data into a "fast, replicable, objective, efficient, scalable, and cost-effective way to assess and quantify urban forest dynamics at varying spatiotemporal scales” (Li et al., 2019, p. 2; Lin et al., 2015; Poon, 2018; Tigges & Lakes, 2017). Research conducted by Li et al. (2019) and Poon (2018) explored the importance of improving methods to quantify urban forests while other analyses such as those conducted by Lin et al. (2015), Ren et al. (2015) and Tigges & Lakes (2017), have examined the strengths and limitations of available software.
One area of consensus, though, is that the relatively cost-effective nature of these technologies make them into an important area of future research and an invaluable tool that is particularly attractive to advocates for open-data initiatives (Silva et al, 2018). Subsequently, these researchers have designed several software packages for the open-source data analysis language R (Silva et al., 2018). It is the goal of this project to examine these software packages and produce a guide that determines the current feasibility of conducting remote tree censuses in an open-source format when the appropriate LiDAR data is available.
Remote Tree Census Tools
Although the field of remote tree identification is relatively new (the first R package for LiDAR data analysis was developed in 2014), the number of open-source tools available has expanded quickly. In this tutorial, we will be examining the tools available to conduct tree censuses with LiDAR data in R/RStudio.
LiDAR
What is LiDAR data?
LiDAR is an acronym for Light Detection And Ranging.
The National Ocean Service of the National Oceanic and Atmospheric Administration (NOAA) describes it as “a remote sensing method that uses light in the form of a pulsed laser to measure ranges (variable distances) to the Earth. These light pulses—combined with other data recorded by the airborne system — generate precise, three-dimensional information about the shape of the Earth and its surface characteristics…[t]opographic lidar typically uses a near-infrared laser to map the land.”
Further, the NOAA explains the process of collecting LiDAR data in the following way:
When an airborne laser is pointed at a targeted area on the ground, the beam of light is reflected by the surface it encounters. A sensor records this reflected light to measure a range. When laser ranges are combined with position and orientation data generated from integrated GPS and Inertial Measurement Unit systems, scan angles, and calibration data, the result is a dense, detail-rich group of elevation points, called a “point cloud.”
Each point in the point cloud has three-dimensional spatial coordinates (latitude, longitude, and height) that correspond to a particular point on the Earth’s surface from which a laser pulse was reflected. The point clouds are used to generate other geospatial products, such as digital elevation models, canopy models, building models, and contours.
You can read more on the NOAA website here.
The following websites provide access to free, publicly available LiDAR data sets:
R and RStudio
What is R?

R is an open-source programming environment that was developed for statistical and graphical analysis. The functionality of the environment is easily extended through the installation of software packages that can perform a wide variety of analyses.
You can read more about R and download the software from the Comprehensive R Archive Network (CRAN) for installation on a Linux, Mac OS X, or Windows device by clicking here.
What is RStudio?
RStudio Desktop is an open-source software that provides a graphical user interface to run R code and create a variety of document types (such as .html, markdown, .pdf, .docx) that include R code and output.
You can learn more about the software and install it on your device by clicking here.
Remote Tree Census Code-Through
The following steps will guide you through the process of setting up RStudio and conducting the tree census.
Set-Up
Once you have R and RStudio installed, open RStudio and create a new file of your choice. You may find it easiest to create an RMarkdown file as displayed below:
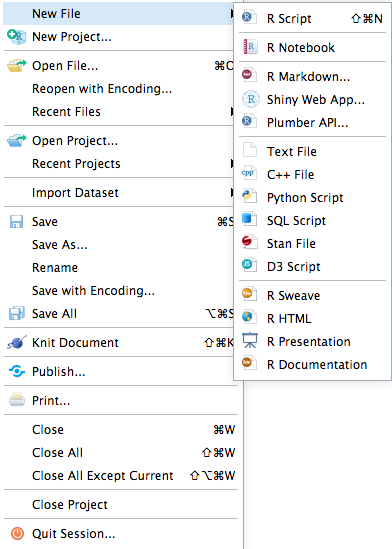
If you select the RMarkdown option, you will get the following dialog box:
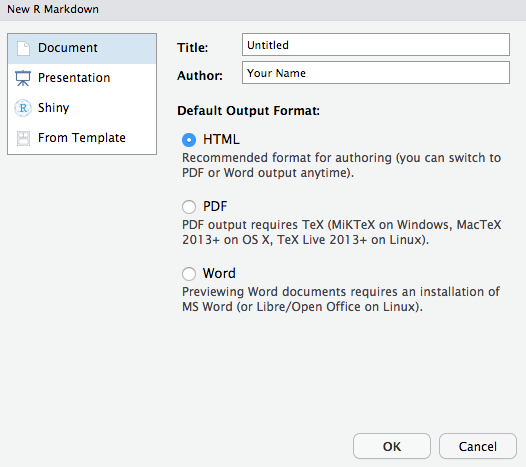
Select the option of your choice for document type. You can change this selection later using any of the multitude of RMarkdown output formats detailed here. This document was created using the Github document option:
Packages
Installation
Once RStudio is set up, copy and paste the following code into the Console to install the packages that we will need for the tree census:
# Install Packages
install.packages( "here" )
install.packages( "lidR" )
install.packages( "rLiDAR" )
install.pacakges( "raster" )
install.packages( "sp" )
install.packages( "ggmap" )
install.packages( "measurements" )
install.packages( "kableExtra" )
install.packages( "tidyverse" )
Another option is to use the insert button to create an R Code chunk that you will copy and paste the code into and run once. After the packages are installed, add eval=FALSE to the top of the code chunk.


Library
Once the packages are installed, add them to a code chunk in your RMarkdown file using the library() function:
# Library
library( "here" ) # Used to create relative file paths so that code is reproducible
library( "lidR" ) # Used for LiDAR file processing
library( "rLiDAR" ) # Used for LiDAR file processing
library( "raster" ) # Used for raster file processing
library( "sp" ) # Used for mapping and spatial data processing
library( "ggmap" ) # Used for mapping and spatial data processing
library( "measurements" ) # Used to convert measurement units
library( "kableExtra" ) # Used to format tables
library( "tidyverse" ) # Used for manipulating data and packages
Although there are a wide variety of packages available for processing geospatial and LiDAR data in R, these selected packages are user-friendly and capable of analyzing the data in its raw form. Some other packages such as ForestTools require some pre-processing of the data. We will be working with a raw data set in this tutorial and coding all height models directly in R.
The documentation and reference manuals for the packages are available on CRAN:
Data
Now that we have RStudio set up and our needed packages installed, we need to load our LiDAR data set.
For this tutorial we will be using a set of LiDAR point clouds from Phoenix, Arizona that was collected by the United States Geological Survey (USGS). We retrieved this data set from the Arizona State University Library’s Map and Geospatial Hub. The files are too large for storage on Github, but the CHM raster files are available for reproducibility purposes in the repository for this site here.
Note: LiDAR data sets are relatively large when compared to most data formats. Ensure that you have the necessary storage and processing capacity to run the required analyses. For this tutorial, the ASU Research Computing Facilities’ supercomputer was used to configure an RStudio session with R version 3.6.2 and 6 CPU Cores. In addition, a sufficient amount of RAM is needed. A minimum of 4GB RAM and fewer CPU cores may be used, but you will need to allot time for delayed processing. Click here and here for articles that provide suggestions for appropriate computer configurations.
Data Download
First, you need to ensure that you have your data downloaded and stored in a clearly labeled file for easy reference during your coding process.
Depending on where your data is stored, the code needed for download may vary. The data set used for this tutorial was stored in Dropbox and the following code was used:
# Download LAS LiDAR data
# 2333 tile
download.file( "dropbox_link_here",
"./data/lidar/las-points/lidar_2333_usgs_2014.las" )
# 2433 tile
download.file( "dropbox_link_here",
"./data/lidar/las-points/lidar_2433_usgs_2014.las" )
Dropbox is an excellent tool for hosting larger data sets. You can find tips on importing data from Dropbox into R here.
Note: Some operating systems and/or wifi speeds may have trouble with downloading the entire LAS files from Dropbox. Double check that file sizes match the original source.
Data Exploration
To load the data we will use the following code:
LASfile <- here( "data/lidar/las-points/lidar_2333_usgs_2014.las" )
las <- lidR::readLAS( LASfile )
LASfile2 <- here( "data/lidar/las-points/lidar_2433_usgs_2014.las" )
las2 <- lidR::readLAS( LASfile2 )
The here() function stores the LiDAR data into the LASfile variable. This variable is then used with the lidR package function readLAS to properly import the LiDAR point cloud data.
Next, we can use base R functions to explore the LiDAR data sets further. For the purposes of the tutorial, we will summarize our first data set:
summary( las ) # 11.25 million points over 1.04 km^2
## class : LAS (v1.2 format 1)
## memory : 858.3 Mb
## extent : 397990, 399010, 3704990, 3706010 (xmin, xmax, ymin, ymax)
## coord. ref. : +proj=utm +zone=12 +datum=NAD83 +units=m +no_defs +ellps=GRS80 +towgs84=0,0,0
## area : 1.04 km²
## points : 11.25 million points
## density : 10.81 points/m²
## File signature: LASF
## File source ID: 0
## Global encoding:
## - GPS Time Type: Standard GPS Time
## - Synthetic Return Numbers: no
## - Well Know Text: CRS is GeoTIFF
## - Aggregate Model: false
## Project ID - GUID: 00000000-0000-0000-0000-000000000000
## Version: 1.2
## System identifier:
## Generating software: TerraScan
## File creation d/y: 290/2014
## header size: 227
## Offset to point data: 513
## Num. var. length record: 3
## Point data format: 1
## Point data record length: 28
## Num. of point records: 11250194
## Num. of points by return: 10933801 303379 12794 220 0
## Scale factor X Y Z: 0.001 0.001 1e-05
## Offset X Y Z: 397990 3704990 329.04
## min X Y Z: 397990 3704990 329.04
## max X Y Z: 399010 3706010 363.8
## Variable length records:
## Variable length record 1 of 3
## Description: GeoTiff GeoKeyDirectoryTag
## Tags:
## Key 1024 value 1
## Key 1025 value 1
## Key 1026 value 0
## Key 2049 value 21
## Key 2054 value 9102
## Key 2062 value 0
## Key 3072 value 26912
## Key 3076 value 9001
## Variable length record 2 of 3
## Description: GeoTiff GeoDoubleParamsTag
## data: 0 0 0
## Variable length record 3 of 3
## Description: GeoTiff GeoAsciiParamsTag
## data: NAD83 / UTM zone 12N|NAD83|
The summary output indicates the size of each pixel in the LAS file and indicates that there are 11.25 million points spread over 1.04 km^2
# 1,000 meter by 1,000 meter area
sqrt( 11250000 ) # 11,250,000 points
## [1] 3354.102
# 3,354 pixels per side
The square root function further breaks down the analysis to indicate that in a 1,000 meter by 1,000 meter area there are 3,354 pixels per side.
# pixel to area
# 1,000 meters / 3,354 pixels
1000/3354
## [1] 0.2981515
# 0.30 meters per pixel ~ one foot per pixel
We can then divide the area by the pixels to find that there are approximately .30 meters per pixel in the data set. In the United States Customary System (USCS) of measurements, this is equivalent to approx. 1 foot per pixel.
Tree Identification
In order to conduct a tree census, we must first identify individual trees. To accomplish this, we need to normalize the heights of the LAS files, colorize the pixels, and create a Canopy Height Model.
The Canopy Height Model (CHM) finds the distance of objects from the ground and will serve as a measurement tool for analysis.
# Tree identification for 2433 tile
las2 <- normalize_height( las2, tin() ) # Normalize heights
col <- height.colors( 50 ) # Colorize pixels
chm2 <- lidR::grid_canopy( las2, res = 1, p2r() ) # Create Canopy Height Model
# Plot Canopy Height Model
plot( chm2, col = col )
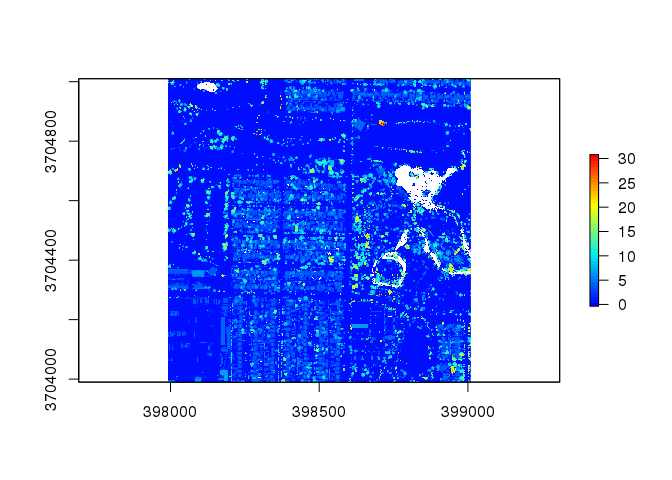
This plot displays the heights of the various items in the LiDAR data tile. Flat areas with a height of 0 meters are displayed in dark blue while tall areas with a height up to 30 meters are displayed in red.
The lidR package’s grid_canopy() function provides several graphing options that can change the appearance of the plot:
chm2 <- lidR::grid_canopy( las2, res = 0.5, p2r() ) # alter the resolution to 0.5
plot( chm2, col = col )
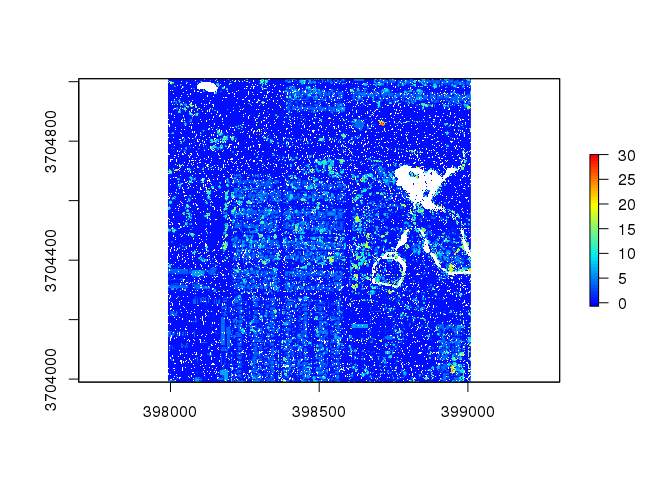
This reduction in the resolution worsens the plot
chm2 <- lidR::grid_canopy( las2, res = 0.5, p2r(0.2) ) # adjust the points-to-raster algorithm's circle size
plot( chm2, col = col )
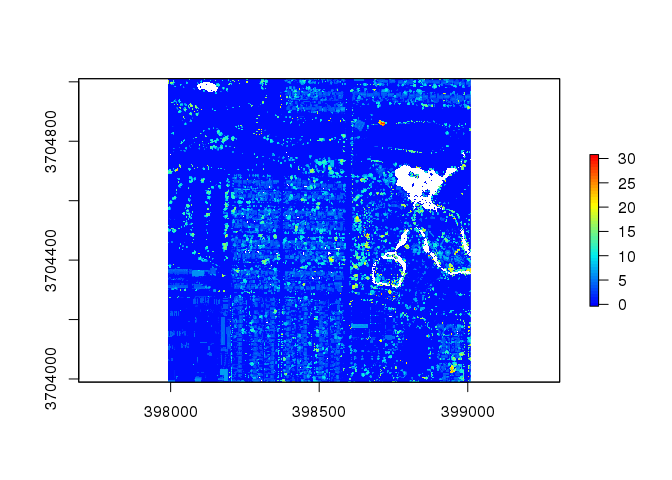
Adjusting the points-to-raster algorithm's circle size slightly improves the graph, but keeps some holes in the plot.
chm2 <- lidR::grid_canopy( las2, res = 2, p2r() ) # alter the resolution to 2
plot( chm2, col = col )
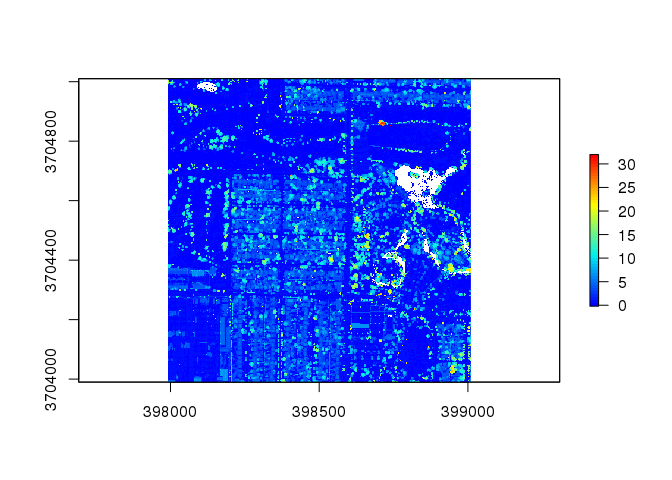
This improves the resolution of the plot, but some holes still remain.
chm2 <- lidR::grid_canopy( las2, res = 2, p2r(0.5) ) # alter the resolution and points-to-raster configurations
plot( chm2, col = col )
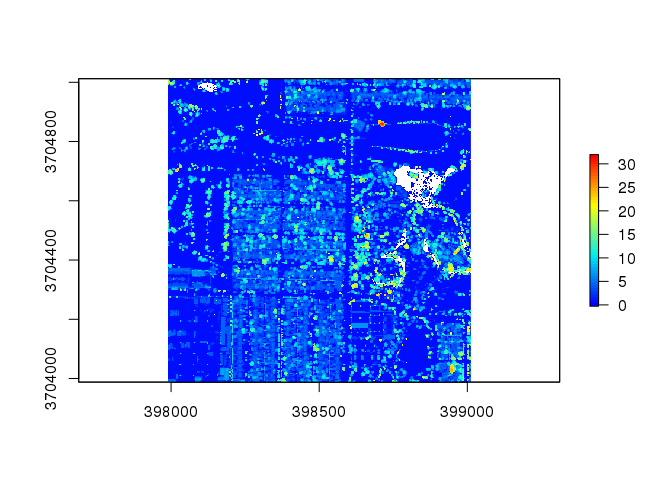
This slightly increases the plot, but there are still some unclear plots. Therefore, we will try the package’s pitfree() function:
Note: This function requires more computer power than the p2r and triangulation based methods that are available in the package’s documentation.
chm2 <- lidR::grid_canopy(las2, 0.25, pitfree(c(0,2,5,10,15), c(0,1), subcircle = 0.2))
# Pitfree plot
plot( chm2, col = col )
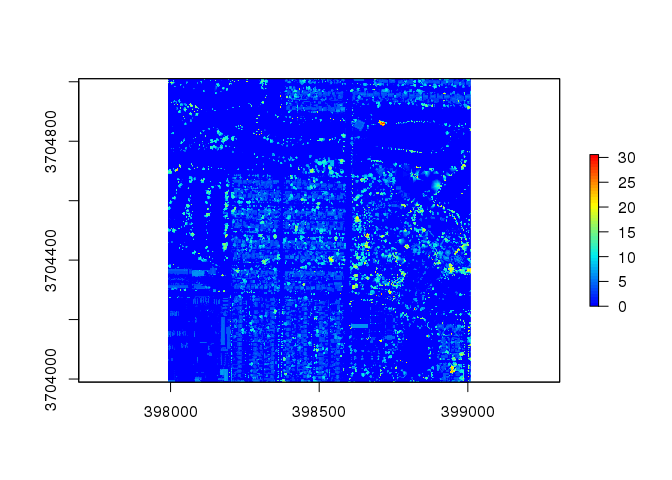
This plot contains very few white spaces and provides a clear colorized analysis of the heights present in the tile.
# Find heights of objects in tile that are at least 1.37 meters tall
trees2 <- FindTreesCHM( chm2 ) # function from rLiDAR package
head( trees2 ) %>% kable() %>% kable_styling() # Create table of data
| x | y | height |
|---|---|---|
| 398400.6 | 3705009 | 3.565190 |
| 398401.9 | 3705009 | 3.421995 |
| 398523.9 | 3705009 | 2.164520 |
| 398578.6 | 3705009 | 7.366430 |
| 398705.1 | 3705009 | 4.276970 |
| 398713.9 | 3705009 | 4.272560 |
After we find the heights of objects in meters, we can also find the measures in feet:
# Create measures in feet and meters
colnames( trees2 ) <- c( "x", "y", "height_meter" ) # rename column to designate meters
head( trees2 ) %>% kable() %>% kable_styling() # preview data set with new column titles
| x | y | height_meter |
|---|---|---|
| 398400.6 | 3705009 | 3.565190 |
| 398401.9 | 3705009 | 3.421995 |
| 398523.9 | 3705009 | 2.164520 |
| 398578.6 | 3705009 | 7.366430 |
| 398705.1 | 3705009 | 4.276970 |
| 398713.9 | 3705009 | 4.272560 |
trees2$height_ft <- conv_unit( trees2$height_meter, "m", "ft" ) # create column with tree heights in feet
head( trees2 ) %>% kable() %>% kable_styling() # view new data set with measures in feet
| x | y | height_meter | height_ft |
|---|---|---|---|
| 398400.6 | 3705009 | 3.565190 | 11.696818 |
| 398401.9 | 3705009 | 3.421995 | 11.227019 |
| 398523.9 | 3705009 | 2.164520 | 7.101444 |
| 398578.6 | 3705009 | 7.366430 | 24.168077 |
| 398705.1 | 3705009 | 4.276970 | 14.032054 |
| 398713.9 | 3705009 | 4.272560 | 14.017585 |
Now we will repeat these steps for our 2333 tile:
# Tree identification for 2333 tile
# Normalize heights
las <- normalize_height( las, tin() )
# Colorize pixels
col <- height.colors( 50 )
# Create Canopy Height Model
chm <- lidR::grid_canopy( las, res = 1, p2r() ) # This LiDAR tile's colorization does not change much with differing strategies
# Plot 2333 tile
plot( chm, col = col )
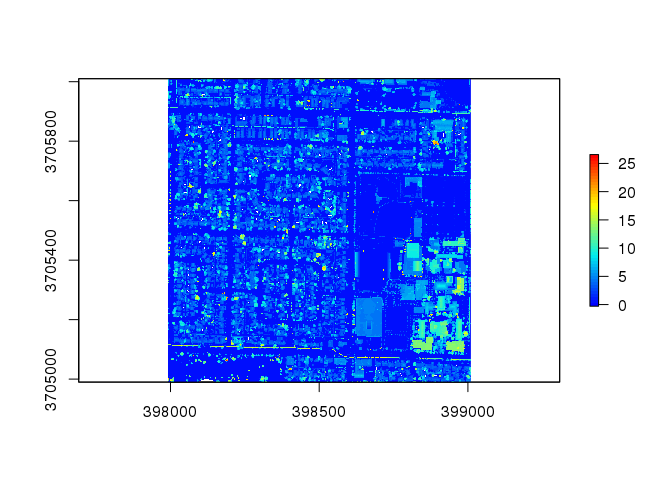
# Find trees
trees <- FindTreesCHM( chm )
head( trees ) %>% kable() %>% kable_styling()
| x | y | height |
|---|---|---|
| 398074.1 | 3706009 | 7.155665 |
| 398102.9 | 3706009 | 5.658660 |
| 398103.1 | 3706009 | 5.658660 |
| 398108.4 | 3706009 | 5.650502 |
| 398126.6 | 3706009 | 11.269140 |
| 398130.9 | 3706009 | 8.827670 |
# Create measures in feet and meters
colnames( trees ) <- c( "x", "y", "height_meter" ) # rename column to designate meters
head( trees ) %>% kable() %>% kable_styling() # preview data set with new column titles
| x | y | height_meter |
|---|---|---|
| 398074.1 | 3706009 | 7.155665 |
| 398102.9 | 3706009 | 5.658660 |
| 398103.1 | 3706009 | 5.658660 |
| 398108.4 | 3706009 | 5.650502 |
| 398126.6 | 3706009 | 11.269140 |
| 398130.9 | 3706009 | 8.827670 |
trees$height_ft <- conv_unit( trees$height_meter, "m", "ft" ) # create column with tree heights in feet
head( trees ) %>% kable() %>% kable_styling() # view data set with measures in feet
| x | y | height_meter | height_ft |
|---|---|---|---|
| 398074.1 | 3706009 | 7.155665 | 23.47659 |
| 398102.9 | 3706009 | 5.658660 | 18.56516 |
| 398103.1 | 3706009 | 5.658660 | 18.56516 |
| 398108.4 | 3706009 | 5.650502 | 18.53839 |
| 398126.6 | 3706009 | 11.269140 | 36.97224 |
| 398130.9 | 3706009 | 8.827670 | 28.96217 |
Once we have our data set created, we can then narrow the area of the plot to create a sample area to conduct our remote tree census:
# Create fixed square window size of 5 for an area to conduct a sample tree census
trees <- FindTreesCHM( chm, fws=5 )
# Create measures in feet and meters
colnames( trees ) <- c( "x", "y", "height_meter" ) # rename column to designate meters
head( trees ) %>% kable() %>% kable_styling() # preview data set with new column titles
| x | y | height_meter |
|---|---|---|
| 398074.1 | 3706009 | 7.155665 |
| 398102.9 | 3706009 | 5.658660 |
| 398103.1 | 3706009 | 5.658660 |
| 398108.4 | 3706009 | 5.650502 |
| 398126.6 | 3706009 | 11.269140 |
| 398130.9 | 3706009 | 8.827670 |
trees$height_ft <- conv_unit( trees$height_meter, "m", "ft" ) # create column with tree heights in feet
head( trees ) %>% kable() %>% kable_styling() # view data set with measures in feet
| x | y | height_meter | height_ft |
|---|---|---|---|
| 398074.1 | 3706009 | 7.155665 | 23.47659 |
| 398102.9 | 3706009 | 5.658660 | 18.56516 |
| 398103.1 | 3706009 | 5.658660 | 18.56516 |
| 398108.4 | 3706009 | 5.650502 | 18.53839 |
| 398126.6 | 3706009 | 11.269140 | 36.97224 |
| 398130.9 | 3706009 | 8.827670 | 28.96217 |
summary( trees ) %>% kable() %>% kable_styling()
| x | y | height_meter | height_ft |
|---|---|---|---|
| Min. :397991 | Min. :3704991 | Min. : 1.495 | Min. : 4.905 |
| 1st Qu.:398277 | 1st Qu.:3705224 | 1st Qu.: 3.973 | 1st Qu.:13.033 |
| Median :398527 | Median :3705425 | Median : 4.925 | Median :16.157 |
| Mean :398527 | Mean :3705468 | Mean : 6.190 | Mean :20.307 |
| 3rd Qu.:398812 | 3rd Qu.:3705732 | 3rd Qu.: 7.770 | 3rd Qu.:25.493 |
| Max. :399009 | Max. :3706009 | Max. :27.568 | Max. :90.445 |
We can save the raster file of the plot and the CSV file of tree height data with the following functions:
# Save tree heights to CSV file
write.csv( trees, here("data/csv/trees_2333.csv") )
# Save Canopy Height Model to raster file
writeRaster( chm, here("data/lidar/raster/2333.tif") )
To view the saved CSV file, we can run the following code:
# Preview CSV file
head ( read.csv( here("data/csv/trees_2333.csv"), col.names = c("id", "x", "y", "height_meter", "height_ft"), stringsAsFactors = FALSE ) ) %>% kable() %>% kable_styling()
| id | x | y | height_meter | height_ft |
|---|---|---|---|---|
| 1 | 398074.1 | 3706009 | 7.155665 | 23.47659 |
| 2 | 398102.9 | 3706009 | 5.658660 | 18.56516 |
| 3 | 398103.1 | 3706009 | 5.658660 | 18.56516 |
| 4 | 398108.4 | 3706009 | 5.650502 | 18.53839 |
| 5 | 398126.6 | 3706009 | 11.269140 | 36.97224 |
| 6 | 398130.9 | 3706009 | 8.827670 | 28.96217 |
To view the saved raster file, we can run the following code:
# Preview Raster file
raster.2333 <- raster( here("data/lidar/raster/2333.tif") )
plot( raster.2333, col = col )
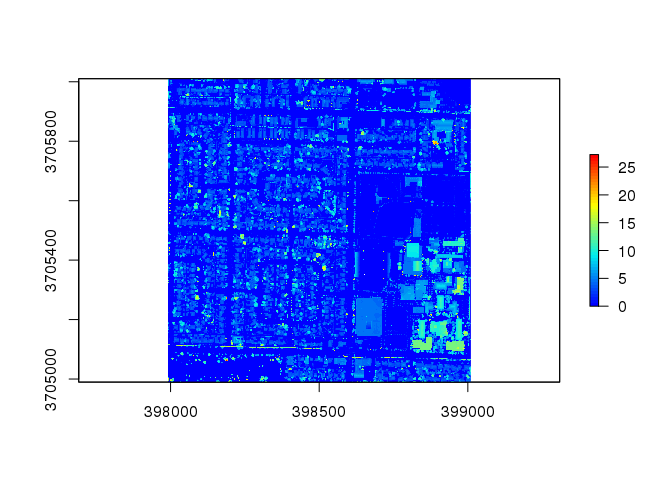
Mapping Trees
Automatic
Now that we have a Canopy Height Model raster file created, we can map our trees using the sp and ggmap packages.
Note: For this tutorial, we will use Google Maps to conduct our automated vs manual remote tree census comparison. However, since Google Maps are proprietary, to access them you must request an API code from Google’s Cloud Services and keep a credit card on record with Google. If you would like a completely open-source mapping option, ggmap also supports OpenStreetMap and Stamen Maps. Details on these mapping options are available here.
If you decide to use Google Maps, you will need to run the following code to register your API key before following the rest of the tutorial:
register_google( key = "[your API key]" ) # for temporary use of key
register_google( key = "[your API key]", write = TRUE ) # for permanently registering key in .Renviron file
More details on ggmap’s Google API key requirements can be found on the package’s Github repo.
To begin the mapping process, first we must use the sp package to convert our LiDAR 3D point cloud dimensions into traditional latitude and longitude measurements. We will store these in the lat.lon variable:
coords <- trees[ c("x","y") ]
names( trees ) <- c("id", "x.meters","y.meters","height")
crs <- sp::CRS( "+proj=utm +zone=12 +datum=NAD83 +units=m +no_defs" )
df <- sp::SpatialPointsDataFrame( coords, proj4string=crs, data=trees )
df2 <- spTransform( df, CRS("+proj=longlat +datum=WGS84") )
lat.lon <- coordinates( df2 ) %>% as.data.frame()
lat.lon$height <- trees$height
Next, we will use ggmap to plot the locations of our trees on a map:
# Open-Source Stamen version
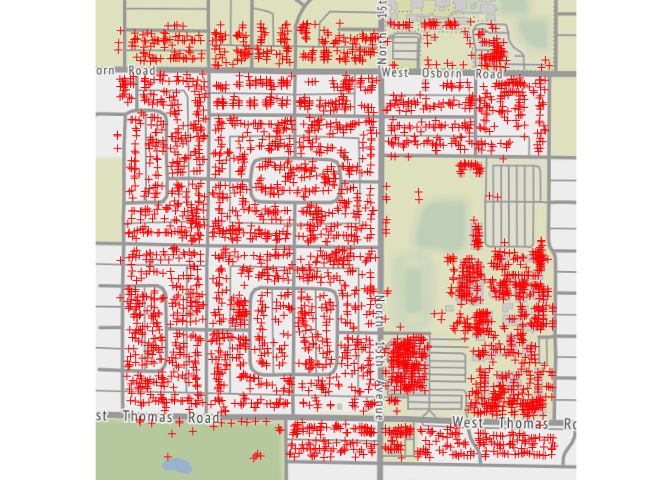
qmplot( x, y, data = lat.lon, geom="blank",
source="stamen", maptype = "terrain" ) +
geom_point( shape=3, color="red" )
# Google Maps version requiring API key
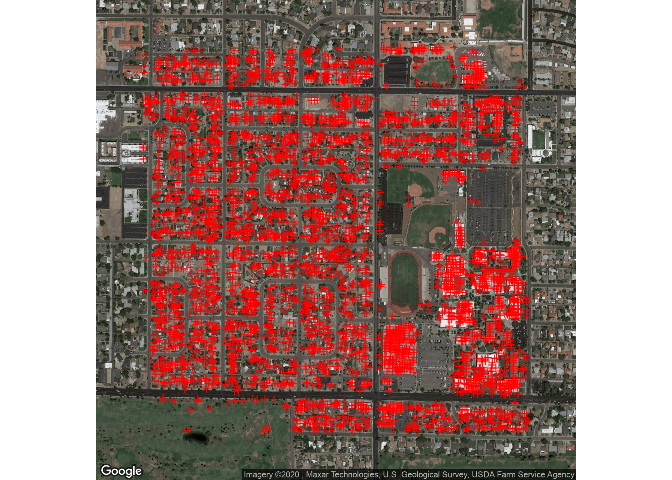
qmplot( x, y, data = lat.lon, geom="blank",
source="google", maptype = "satellite" ) +
geom_point( shape=3, color="red" )
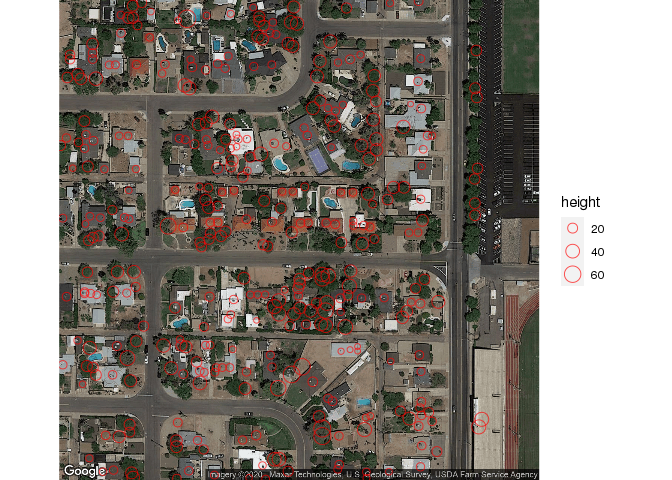
If we zoom into the map at level of 18, we can see the individual trees and get a general idea of the automatic mapping function’s effectiveness:
# zoomed view
googleplot <- qmplot( x, y, data = lat.lon, geom = "blank", zoom=18,
source="google", maptype = "satellite" ) +
geom_point( shape=1, color="red", alpha=0.7, aes( size=height, max=5 ) )
googleplot
We can review the latitude and longitude of the identified trees by examining the `lat.lon` data:
lat.lon.csv <- lat.lon
# label columns
names( lat.lon.csv ) <- c( "longitude","latitude","height" )
# order columns
lat.lon.csv <- lat.lon.csv[,c("latitude","longitude","height")]
# view longitude, latitude, and height of trees
head( lat.lon.csv ) %>% kable() %>% kable_styling()
| latitude | longitude | height |
|---|---|---|
| 33.48878 | -112.0911 | 19.94970 |
| 33.48872 | -112.0965 | 28.90515 |
| 33.48874 | -112.0944 | 11.71522 |
| 33.48875 | -112.0932 | 13.27365 |
| 33.48876 | -112.0924 | 43.65115 |
| 33.48877 | -112.0907 | 20.22690 |
We can also create an output of this data that can be copied and pasted into a data set for sample analysis of 25 trees:
lat.lon.sample <- head( lat.lon.csv, 25 )
dput( lat.lon.sample )
## structure(list(latitude = c(33.4887765925544, 33.4887200718144,
## 33.4887387207169, 33.4887490762573, 33.4887562900649, 33.488771743582,
## 33.4887761002053, 33.4887769523569, 33.4887803602062, 33.4887816851538,
## 33.4887852805171, 33.4887207633205, 33.4887354993676, 33.4887682183598,
## 33.4887687864017, 33.4887000355671, 33.4887014643409, 33.4887166915127,
## 33.4887301855912, 33.4887327492348, 33.4887570225238, 33.4887584428876,
## 33.4886943510338, 33.4887171783276, 33.4887218322838), longitude = c(-112.091129870331,
## -112.096511055517, -112.094401588091, -112.09322846506, -112.092410507362,
## -112.090656202371, -112.090161122193, -112.090064258668, -112.089676804525,
## -112.089526127896, -112.089117148426, -112.095413158141, -112.093744956394,
## -112.090031857833, -112.089967282153, -112.096736842396, -112.09657540368,
## -112.094853390005, -112.093325101785, -112.093034511656, -112.090279284906,
## -112.090117845736, -112.096360038394, -112.093777017421, -112.093249650282
## ), height = c(19.9497047244094, 28.9051509186352, 11.7152230971129,
## 13.2736548556431, 43.6511482939632, 20.2269028871392, 19.9992454068242,
## 20.0284448818898, 20.5833661417322, 20.0889107611549, 31.4985892388452,
## 16.6064304461943, 12.3624999999999, 20.0950787401575, 20.3713582677165,
## 26.7971784776903, 35.7228346456694, 13.0542322834645, 28.2633530183727,
## 41.6245078740157, 51.1814632545931, 19.841371391076, 16.5540354330708,
## 12.7031496062992, 12.7728346456692)), row.names = c("1", "2",
## "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14",
## "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25"
## ), class = "data.frame")
The complete latitude, longitude, and height data can be saved to a CSV file with the following code:
write.csv( lat.lon.csv, here("data/csv/lat-lon.csv") )
Similarly, the zoomed view of the map can also be saved in PDF and PNG format:
# Save to PDF
pdf( here("data/output/trees-plot.pdf") )
# zoomed view
qmplot( x, y, data = lat.lon, geom = "blank", zoom=18,
source="google", maptype = "satellite" ) +
geom_point( shape=1, color="red", alpha=0.7, aes( size=height, max=5 ) )
dev.off()
# Save to PNG
png( here("data/output/trees-plot.png") )
# zoomed view
qmplot( x, y, data = lat.lon, geom = "blank", zoom=18,
source="google", maptype = "satellite" ) +
geom_point( shape=1, color="red", alpha=0.7, aes( size=height, max=5 ) )
dev.off()
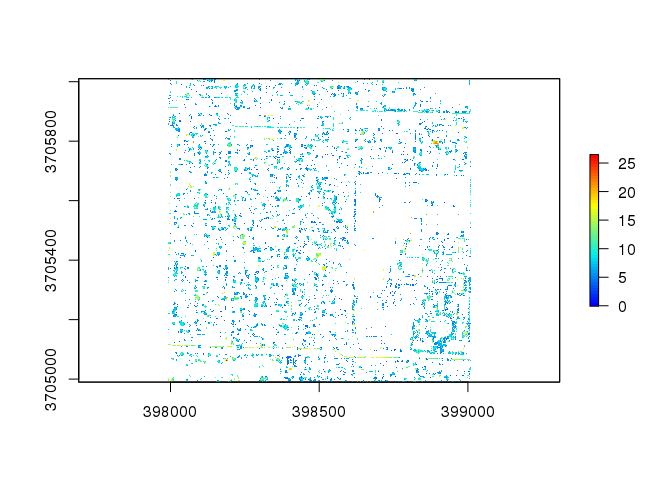
Another option for tree identification is to use the filter_poi() option to filter out all pointclouds that are not high vegetation:
las3 <- filter_poi( las, Classification == LASHIGHVEGETATION )
chm3 <- lidR::grid_canopy( las3, res = 1, p2r() )
plot( chm3, col = col )
trees3 <- FindTreesCHM( chm3, fws=5 )
head( trees3 ) %>% kable() %>% kable_styling()
| x | y | height |
|---|---|---|
| 398457.5 | 3706000 | 11.98587 |
| 398428.5 | 3706000 | 8.81709 |
| 398719.5 | 3705978 | 11.07696 |
| 398724.5 | 3705976 | 10.55877 |
| 398481.5 | 3705964 | 10.11997 |
| 398861.5 | 3705904 | 9.98835 |
However, as displayed here, the high vegetation filter not only removes excess point clouds, it also severely reduces the number of trees identified:
coords <- trees3[ c("x","y") ]
names( trees3 ) <- c( "x.meters","y.meters","height")
crs2 <- sp::CRS( "+proj=utm +zone=12 +datum=NAD83 +units=m +no_defs" )
df3 <- sp::SpatialPointsDataFrame( coords, proj4string=crs, data=trees3 )
df4 <- spTransform( df3, CRS("+proj=longlat +datum=WGS84") )
lat.lon2 <- coordinates( df4 ) %>% as.data.frame()
lat.lon2$height <- trees3$height
qmplot( x, y, data = lat.lon2, geom = "blank", zoom=18,
source="google", maptype = "satellite" ) +
geom_point( shape=1, color="red", alpha=0.7, aes( size=height, max=5 ) )
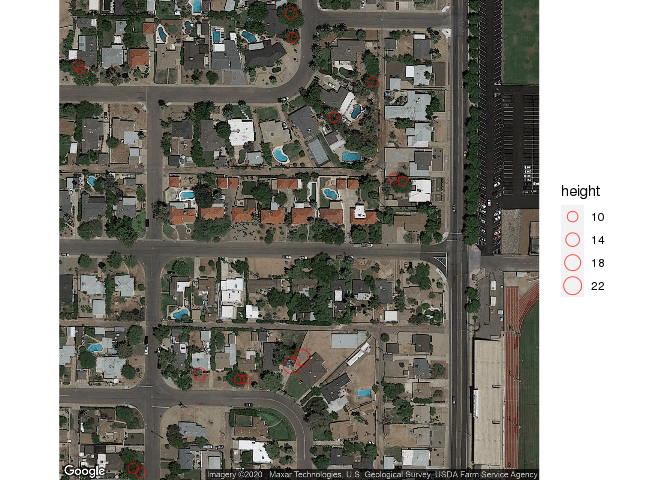
Therefore, we will use the complete unfiltered point cloud set:
# zoomed view
googleplot <- qmplot( x, y, data = lat.lon, geom = "blank", zoom=18,
source="google", maptype = "satellite" ) +
geom_point( shape=1, color="red", alpha=0.7, aes( size=height, max=5 ) )
googleplot
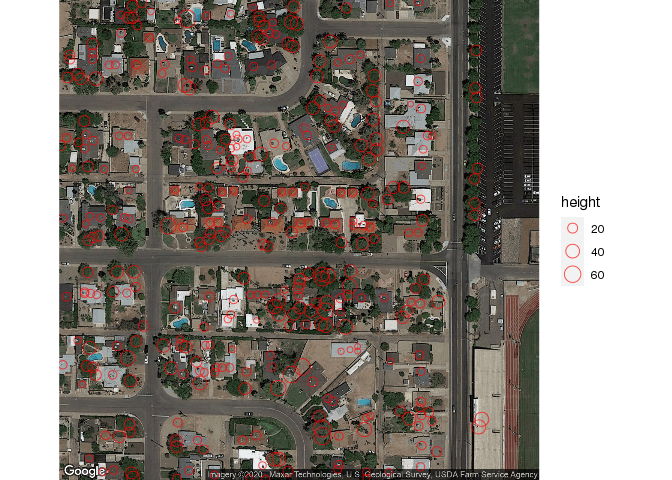
Manual
Using the coordinates we found in our CSV file, we can upload the plots to the free mapping software Google MyMaps:
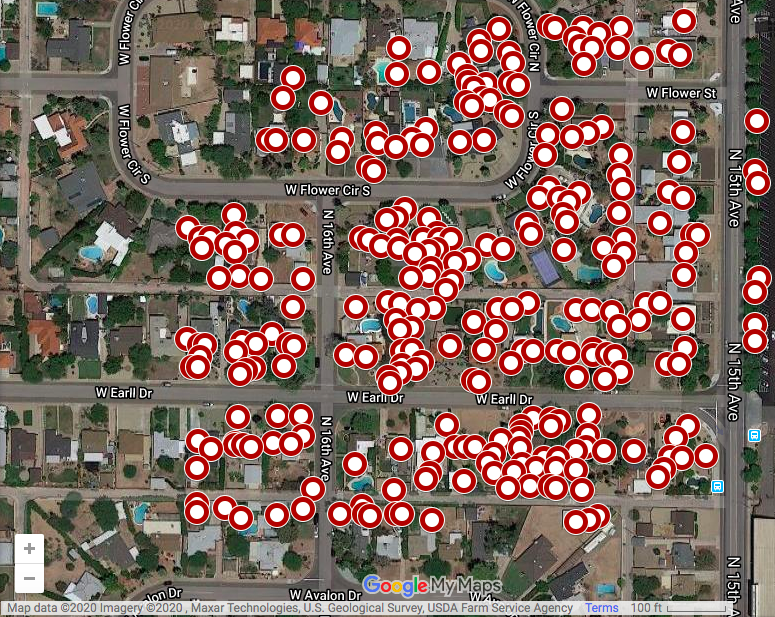
Google MyMaps also allows us to conduct a manual tree census where we can plot all of the trees individually on the map.
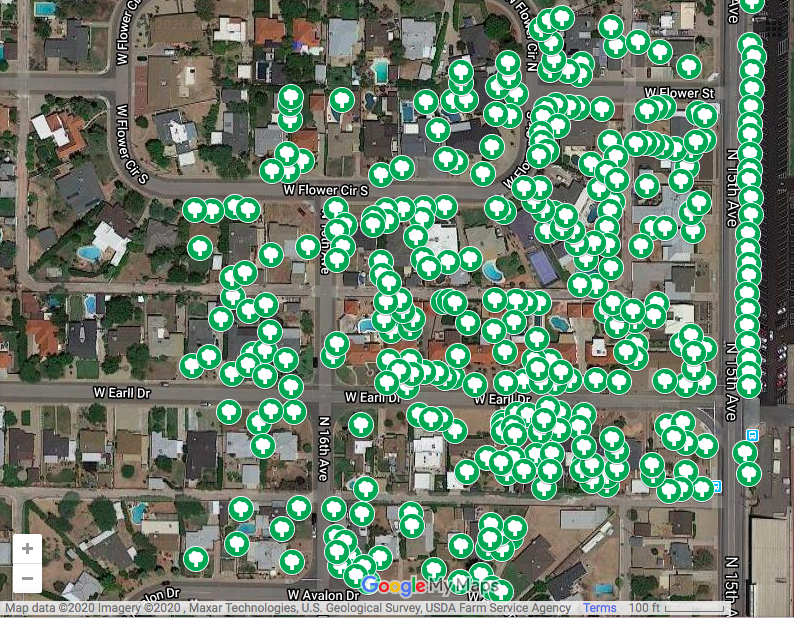
A compilation of the layers allows us to see the overlap and discrepancies between manual remote tree identification and the automated algorithm. The green trees were marked manually and the red circles were identified by the coded algorithm:
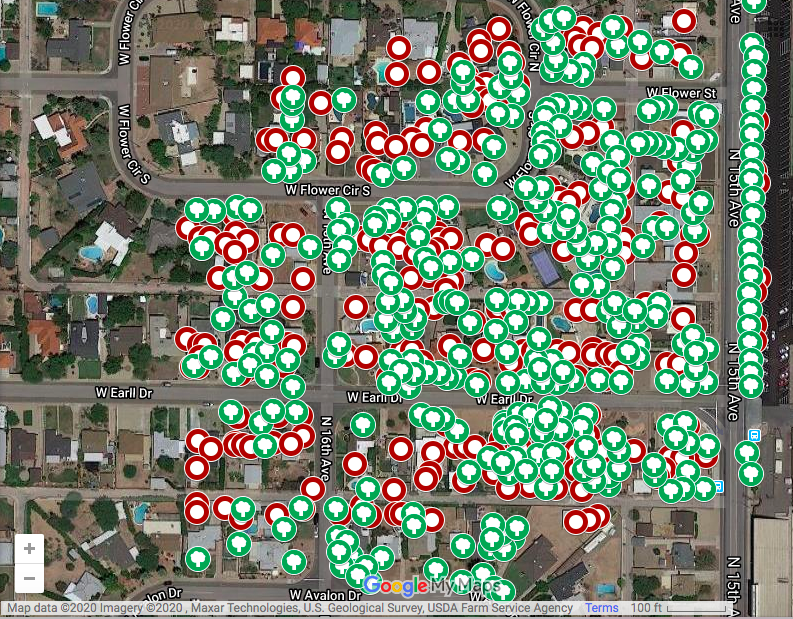
Comparison
An interactive version of the Google MyMap can be explored here:
To view the automated and manual plot layers, click the button to the left of the Tree Census title:

This will open the option to select between the imported layer of automated data points that was generated from the lat-lon CSV and the manually marked trees:
Discussion
The automated tree census identified 278 trees in the sample census area while the manual tree census found 321 trees. This indicates that the algorithm was 86.6% accurate.
The automated tree census had some flaws, particularly in the area of misidentifying tall, narrow points on buildings as trees, overlooking palm trees due to their small circumference/crown shape, and miscounting overlapping trees in heavily canvassed areas.
However, the algorithm did not seem to fall prey to serious systematic or measurement errors that could severely bias results—it consistently undercounted trees and overcounted buildings on all the blocks in the sample area. Therefore, the miscounts balance out.
Overall, the open-source tools for conducting remote-tree censuses are extremely advanced and relatively accurate. They provide a promising solution to provide a baseline estimate of the number of trees located in sparsely canvassed areas before organizations invest in costly traditional tree census methods.
Future research to further explore potential areas of systematic and measurement bias and identify better methods for point cloud layer filteration can make these tools even more effective for non-profit and governmental organizations that need to conduct remote tree censuses.
References
-
Arizona State University Map and Geospatial Hub. (n.d.). New web map for accessing Phoenix LiDAR data. Retrieved July 5, 2020, from https://lib.asu.edu/Geo/news/New-Web-Map-Accessing-Phoenix-LiDAR-Data
-
ASU Research Computing. (n.d.). Retrieved July 5, 2020, from https://cores.research.asu.edu/research-computing/about
-
Benefits of trees. (2019). Nature Climate Change, 9(8), 569–569. doi:10.1038/s41558-019-0556-z
-
Birk, M. A. (2019, May 28). measurements: Tools for Units of Measurement. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=measurements
-
Butt, N., Slade, E., Thompson, J., Malhi, Y., & Riutta, T. (2013). Quantifying the sampling error in tree census measurements by volunteers and its effect on carbon stock estimates. Ecological Applications, 23(4), 936–943. doi:10.1890/11-2059.1
-
Daams, M. N. & Veneri, P. (2016). Living near to attractive nature? A well-being indicator for ranking Dutch, Danish, and German functional urban areas. Social Indicators Research, 133(2), 501–526.
-
Dadvand, P., Villanueva, C. M., Font-Ribera, L., Martinez, D., Basagaña, X., Belmonte, J., Vrijheid, M., Gražulevičiene, R., Kogevinas, M., & Nieuwenhuijsen, M. J. (2014). Risks and benefits of green spaces for children: A cross-sectional study of associations with sedentary behavior, obesity, asthma, and allergy. Environmental Health Perspectives, 122(12), 1329–1335. doi:10.1289/ehp.1308038
-
Dadvand, P., Poursafa, P., Heshmat, R., Motlagh, M., Qorbani, M., Basagaña, X., & Kelishadi, R. (2018). Use of green spaces and blood glucose in children; a population-based CASPIAN-V study. Environmental Pollution, 243(Pt B), 1134–1140. https://doi.org/10.1016/j.envpol.2018.09.094
-
De Vries, S. I., Bakker, I., Van Mechelen, W., & Hopman-Rock, M. (2007). Determinants of activity-friendly neighborhoods for children: Results from the SPACE study. American Journal of Health Promotion: AJHP, 21(4), 312–316.
-
Donovan, G. (2017). Including public-health benefits of trees in urban-forestry decision making. Urban Forestry & Urban Greening, 22, 120–123. https://doi.org/10.1016/j.ufug.2017.02.010
-
Endreny, T. (2018, April 27). The multi-million-dollar benefits of urban trees. Retrieved May 25, 2020, from https://www.citylab.com/environment/2018/04/heres-how-much-money-trees-save-in-megacities/559211/
-
Faber Taylor, A., & Kuo, F. (2011). Could exposure to everyday green spaces help treat ADHD? Evidence from children’s play settings. Applied Psychology: Health and Well‐Being, 3(3), 281–303. https://doi.org/10.1111/j.1758-0854.2011.01052.x
-
Gatziolis, D. & Andersen, H. (2008). A guide to LIDAR data acquisition and processing for the forests of the Pacific Northwest. United States Department of Agriculture Forest Service. Retrieved July 5, 2020, from https://www.fs.fed.us/pnw/pubs/pnw_gtr768.pdf
-
Google. (n.d.). Google Cloud Maps Platform. Retrieved July 7, 2020, from https://cloud.google.com/maps-platform/
-
Google. (n.d.). Google MyMaps Creator. Retrieved July 7, 2020, from https://www.google.com/maps/about/mymaps/
-
Hijmans, R. J. et al. (2020, June 27). raster: Geographic Data Analysis and Modeling. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=raster
-
Jean-Romain. (2020, February 13). Rasterizing perfect canopy height models. Retrieved July 7, 2020, from https://github.com/Jean-Romain/lidR/wiki/Rasterizing-perfect-canopy-height-models
-
Johnson, M., Gonzalez, A., Kozak, B., & Sperlak, L. (2013). Carbon estimation and offsets for U.S. university aviation programs. Collegiate Aviation Review, 31(1), 40–56. https://doi.org/10.22488/okstate.18.100437
-
Kabisch, N., van den Bosch, M., & Lafortezza, R. (2017). The health benefits of nature-based solutions to urbanization challenges for children and the elderly – A systematic review. Environmental Research, 159, 362–373. doi:10.1016/j.envres.2017.08.004
-
Kahle, D. (2019, May 11). ggmap Github Repository. Retrieved July 7, 2020, from https://github.com/dkahle/ggmap
-
Kahle, D. et al. (2019, February 5). ggmap: Spatial Visualization with ggplot2. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=ggmap
-
King, D. K., Litt, J., Hale, J., Burniece, K. M., & Ross, C. (2015). “The park a tree built”: Evaluating how a park development project impacted where people play. Urban Forestry & Urban Greening, 14(2), 293–299. doi:10.1016/j.ufug.2015.02.011
-
Lecy, J. (2016, April 2). Load data files from Dropbox. Retrieved July 5, 2020, from https://github.com/lecy/Import-Data-Into-R/blob/master/import%20from%20dropbox.md
-
Li, X., Chen, W. Y., Sanesi, G., & Lafortezza, R. (2019). Remote sensing in urban forestry: Recent applications and future directions. Remote Sensing, 11(10) doi:10.3390/rs11101144
-
Lin, Y., Jiang, M., Yao, Y., Zhang, L., & Lin, J. (2015). Use of UAV oblique imaging for the detection of individual trees in residential environments. Urban Forestry & Urban Greening, 14(2), 404–412. doi:10.1016/j.ufug.2015.03.003
-
Malmsheimer, R. W., Bowyer, J. L., Fried, J. S., Gee, E., Izlar, R., Miner, R. A., Munn, I. A., Oneil, E., & Stewart, W. C. (2011). Managing forests because carbon matters: Integrating energy, products, and land management policy. Journal of Forestry, 109(7), S7-S50. Retrieved May 31, 2020, from https://www.fs.usda.gov/treesearch/pubs/40291
-
McPherson, E., & Simpson, J. (1999). Carbon dioxide reduction through urban forestry: guidelines for professional and volunteer tree planters. Albany, Calif: U.S. Dept. of Agriculture, Forest Service, Pacific Southwest Research Station. Retrieved May 31, 2020, from https://permanent.access.gpo.gov/lps94433/psw-gtr171.pdf
-
Muller, K. (2017, May 28). here: A Simpler Way to Find Your Files. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=here
-
National Oceanic and Atmospheric Administration (NOAA) (2020, July 1). What is lidar?. National Ocean Service website. Retrieved July 3, 2020, from https://oceanservice.noaa.gov/facts/lidar.html
-
Pebesma, E. et al. (2020, May 20). sp: Classes and Methods for Spatial Data. Retrieved July 6, 2020 from https://CRAN.R-project.org/package=sp
-
Poon, L. (2018, December 28). Every tree in the city, mapped. Retrieved May 25, 2020, from https://www.citylab.com/environment/2018/12/urban-tree-canopy-maps-artificial-intelligence-descartes-labs/578701/
-
Reid, C., Clougherty, J., Shmool, J., & Kubzansky, L. (2017). Is all urban green space the same? A comparison of the health benefits of trees and grass in New York City. International Journal of Environmental Research and Public Health, 14(11), 1411. doi:10.3390/ijerph14111411
-
Ren, Z., Zheng, H., He, X., Zhang, D., Yu, X., & Shen, G. (2015). Spatial estimation of urban forest structures with Landsat TM data and field measurements. Urban Forestry & Urban Greening, 14(2), 336–344. doi:10.1016/j.ufug.2015.03.008
-
RStudio. (n.d.). RStudio Logo. Retrieved July 4, 2020, from https://rstudio.com/about/logos/
-
Roussel, J. et al. (2020, July 5). lidR: Airborne LiDAR Data Manipulation and Visualization for Forestry Applications. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=lidR
-
Russo, A., Escobedo, F. J., Timilsina, N., & Zerbe, S. (2015). Transportation carbon dioxide emission offsets by public urban trees: A case study in Bolzano, Italy. Urban Forestry & Urban Greening, 14(2), 398–403. doi:10.1016/j.ufug.2015.04.002
-
Silva, C.A. et al. (2017, July 12). rLiDAR: LiDAR Data Processing and Visualization. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=rLiDAR
-
Silva, C. A., Klauberg, C. M., Mohan, M. M., & Bright, B. C. (2018). LiDAR Analysis in R and rLiDAR for Forestry Applications. Retrieved from https://www.researchgate.net/publication/324437694_LiDAR_Analysis_in_R_and_rLiDAR_for_Forestry_Applications
-
Taylor, A. F., Wiley, A., Kuo, F. E., & Sullivan, W. C. (1998). Growing up in the inner city: Green spaces as places to grow. Environment and Behavior, 30(1), 3–27. https://doi.org/10.1177/0013916598301001
-
The R Foundation. (2016). The R logo. Retrieved July 4, 2020, from https://www.r-project.org/logo/
-
Thomson, C. (2020). How to overcome large datasets in point cloud processing. Vercator. Retrieved July 5, 2020, from https://info.vercator.com/blog/how-to-overcome-large-datasets-in-point-cloud-processing
-
Tigges, J., & Lakes, T. (2017). High resolution remote sensing for reducing uncertainties in urban forest carbon offset life cycle assessments. Carbon Balance and Management, 12(1), 1–18. https://doi.org/10.1186/s13021-017-0085-x
-
Toro, M. (2017). Robust USGS LiDAR data for Metro Phoenix now available. Retrieved June 29, 2020 from https://lib.asu.edu/geo/news/trees
-
TreesCount! (2017). Retrieved May 31, 2020, from http://media.nycgovparks.org/images/web/TreesCount/Index.html
-
Turner‐Skoff, J. B., & Cavender, N. (2019). The benefits of trees for livable and sustainable communities. Plants, People, Planet, 1(4), 323–335. doi:10.1002/ppp3.39
-
U.S. Department of Agriculture, Forest Service. (2018). Urban nature for human health and well-being: A research summary for communicating the health benefits of urban trees and green space. FS-1096. Washington, DC. Retrieved May 25, 2020, from https://permanent.access.gpo.gov/gpo91156/urbannatureforhumanhealthandwellbeing_508_01_30_18.pdf
-
USGS. (2014). NGA LiDAR project - Phoenix, AZ. Retrieved July 4, 2020, from ASU Library Map and Geospatial Hub https://lib.asu.edu/geo
-
Ulmer, J. M., Wolf, K. L., Backman, D. R., Tretheway, R. L., Blain, C. J., O’Neil-Dunne, J. P., & Frank, L. D. (2016). Multiple health benefits of urban tree canopy: The mounting evidence for a green prescription. Health & Place, 42, 54–62. doi:10.1016/j.healthplace.2016.08.011
-
University of Chicago Computing for the Social Sciences. (2020, February 18). Drawing raster maps with ggmap. Retrieved July 7, 2020, from https://cfss.uchicago.edu/notes/raster-maps-with-ggmap/#obtain-map-images
-
Wasser, L. (2020). Create a canopy height model with LiDAR data. Retrieved June 29, 2020 from https://www.earthdatascience.org/courses/earth-analytics/lidar-raster-data-r/lidar-chm-dem-dsm/
-
Wickham, H. & RStudio (2019, November 21). tidyverse: Easily Install and Load the ‘Tidyverse’. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=tidyverse
-
Zhao, M., Kong, Z.-H., Escobedo, F. J., & Gao, J. (2010). Impacts of urban forests on offsetting carbon emissions from industrial energy use in Hangzhou, China. Journal of Environmental Management, 91(4), 807–813. doi:10.1016/j.jenvman.2009.10.010
-
Zheng, D., Ducey, M., & Heath, L. (2013). Assessing net carbon sequestration on urban and community forests of northern New England, USA. Urban Forestry & Urban Greening, 12(1), 61–68. https://doi.org/10.1016/j.ufug.2012.10.003
-
Zhu, H. et al. (2019, March 16). kableExtra: Construct Complex Table with ‘kable’ and Pipe Syntax. Retrieved July 6, 2020, from https://CRAN.R-project.org/package=kableExtra
Author
Courtney Stowers is a graduate student completing an M.S. in Program Evaluation and Data Analytics at the Watts College of Public Service and Community Solutions, Arizona State University. Her undergraduate degrees in Family and Human Development and Applied Quantitative Science and work experience as a teaching assistant in college-level family science, research methods, and social statistics courses lend to a special interest in social policy for families and children. She hopes to pursue a career that will allow her to use data science to effect change in the lives of communities throughout the United States and across the globe.
During her free time, she enjoys exploring new coding languages, playing board and card games, baking, solving sticker puzzles, reading (particularly current events news articles and historical, romance, and children's literature), listening to music (especially from 1980s-2010s boybands!), and falling asleep on television shows.
She can be contacted via email at courtney.stowers@asu.edu. You can also visit her Github Page here.
Last updated: July 07, 2020